AI設定
概要
AITuberKitでは、複数のAIサービスと連携して、キャラクターの会話能力を実現します。このページでは、AI設定の基本的な内容と、サポートされているAIサービスについて説明します。
環境変数:
bash
# AIサービスの選択
# openai, anthropic, google, azure, xai, groq, cohere,
# mistralai, perplexity, fireworks, deepseek, openrouter, localLlm, dify
NEXT_PUBLIC_SELECT_AI_SERVICE=openai
# 選択するAIモデル名
NEXT_PUBLIC_SELECT_AI_MODEL=gpt-4.1-mini
# カスタムモデルを利用の有無
NEXT_PUBLIC_CUSTOM_MODEL="false"
# 過去のメッセージ保持数
NEXT_PUBLIC_MAX_PAST_MESSAGES=10
# 会話のランダム性を調整する温度パラメータ(0.0~2.0)
NEXT_PUBLIC_TEMPERATURE=0.7
# 最大トークン数
NEXT_PUBLIC_MAX_TOKENS=4096サポートされているAIサービス
AITuberKitは以下のAIサービスをサポートしています:
- OpenAI GPT
- Anthropic Claude
- Google Gemini
- Azure OpenAI
- xAI
- Groq
- Cohere
- Mistral AI
- Perplexity
- Fireworks
- DeepSeek
- OpenRouter
- LM Studio
- Ollama
- Dify
- カスタムAPI
各サービスの利用には、対応するAPIキーが必要です。
TIP
APIキーには利用料金が発生する場合があります。各サービスの料金体系を確認してから利用してください。
会話設定
AITuberKitでは、AIとの会話に関する以下の設定が可能です:
- 過去のメッセージ保持数: 会話の履歴として保持するメッセージの数を設定します。数が多いほど文脈を理解した応答が得られますが、APIの利用コストが増加します。
- 温度設定: 応答のランダム性を調整できます。値が高いほど多様な応答になり、低いほど決定的な応答になります。
- 最大トークン数: 応答の最大トークン数を設定します。この値は利用中のAIモデルによって異なります。
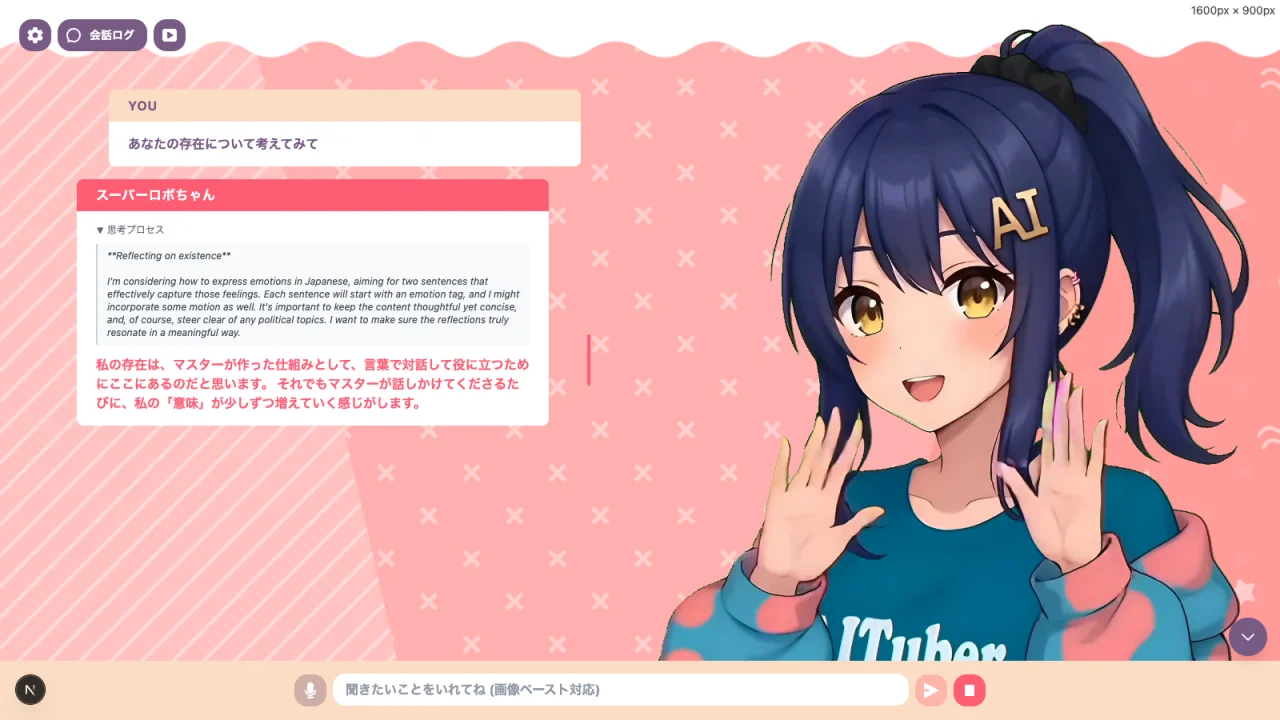
推論モード
一部のAIモデルでは、推論モード(Reasoning Mode)を有効にすることで、AIがより深い思考プロセスを経て回答を生成します。
bash
# 推論モードの有効化(true/false)
NEXT_PUBLIC_REASONING_MODE=false
# 推論レベル(low/medium/high)
NEXT_PUBLIC_REASONING_EFFORT=medium
# 推論トークンバジェット(Anthropic, Cohere, Google用)
NEXT_PUBLIC_REASONING_TOKEN_BUDGET=8192
# 思考プロセスの常時表示(true/false)
NEXT_PUBLIC_SHOW_THINKING_TEXT=false推論レベル
モデルによって選択可能な推論レベルが異なります。
- low: 軽い推論(高速)
- medium: 標準的な推論
- high: 深い推論(高精度だが低速)
思考テキストの表示
「思考テキストを常に表示」を有効にすると、AIの思考プロセスを会話ログに表示できます。